
禁忌搜索
禁忌搜索(英语:Tabu Search,TS,又称禁忌搜寻法)是一种现代启发式算法,由美国科罗拉多大学教授弗雷德·格洛弗于1986年左右提出,并于1989年实现规范化。 这种搜寻法是一个用来跳脱局部最优解的搜索方法。其先创立一个初始化的方案;基于此,算法“移动”到一相邻的方案。经过许多连续的移动过程,提高解的质量。
原文地址:
https://zh.wikipedia.org/wiki/%E7%A6%81%E5%BF%8C%E6%90%9C%E7%B4%A2
在知识共享 署名-相同方式共享 3.0协议之条款下提供
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 张拓的博客!
相关推荐

2022-12-31
八皇后问题
八皇后问题是一个以国际象棋为背景的问题:如何能够在8×8的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行、纵行或斜线上。八皇后问题可以推广为更一般的n皇后摆放问题:这时棋盘的大小变为n×n,而皇后个数也变成n。当且仅当n = 1或n ≥ 4时问题有解。 历史八皇后问题最早是由国际象棋棋手马克斯·贝瑟尔(Max Bezzel)于1848年提出。第一个解在1850年由弗朗兹·诺克(Franz Nauck)给出。并且将其推广为更一般的n皇后摆放问题。诺克也是首先将问题推广到更一般的n皇后摆放问题的人之一。 在此之后,陆续有数学家对其进行研究,其中包括高斯和康托,1874年,S.冈德尔提出了一个通过行列式来求解的方法[2],这个方法后来又被J.W.L.格莱舍加以改进。 1972年,艾兹格·迪杰斯特拉用这个问题为例来说明他所谓结构化编程的能力[3]。他对深度优先搜索回溯算法有着非常详尽的描述2。 八皇后问题在1990年代初期的著名电子游戏《第七访客》和NDS平台的著名电子游戏《雷顿教授与不可思议的小镇》中都有出现。 解题...

2022-12-29
Alpha-beta剪枝
Alpha-beta剪枝是一种搜索算法,用以减少极小化极大算法(Minimax算法)搜索树的节点数。这是一种对抗性搜索算法,主要应用于机器游玩的二人游戏(如井字棋、象棋、围棋)。当算法评估出某策略的后续走法比之前策略的还差时,就会停止计算该策略的后续发展。该算法和极小化极大算法所得结论相同,但剪去了不影响最终决定的分枝。 历史Allen Newell和Herbert A. Simon在1958年,使用了John McCarthy所谓的“近似”alpha-beta算法,此算法当时“应已重新改造过多次”。Arthur Samuel有一个早期版本,同时Richards、Hart、Levine和/或Edwards在美国分别独立发现了alpha-beta。McCarthy在1956年达特默思会议上提出了相似理念,并在1961年建议给他的一群学生,其中包括MIT的Alan Kotok。Alexander Brudno独立发现了alpha-beta算法,并在1963年发布成果。Donald Knuth和Ronald W. Moore在1975年优化了算法,Judea Pearl在1982年证明...
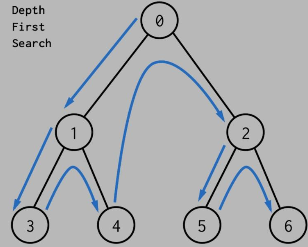
2022-12-25
K-近邻算法
在模式识别领域中,最近邻居法(KNN算法,又译K-近邻算法)是一种用于分类和回归的非参数统计方法。在这两种情况下,输入包含特征空间(Feature Space)中的k个最接近的训练样本。 在k-NN分类中,输出是一个分类族群。一个对象的分类是由其邻居的“多数表决”确定的,k个最近邻居(k为正整数,通常较小)中最常见的分类决定了赋予该对象的类别。若k = 1,则该对象的类别直接由最近的一个节点赋予。 在k-NN回归中,输出是该对象的属性值。该值是其k个最近邻居的值的平均值。最近邻居法采用向量空间模型来分类,概念为相同类别的案例,彼此的相似度高,而可以借由计算与已知类别案例之相似度,来评估未知类别案例可能的分类。 K-NN是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。k-近邻算法是所有的机器学习算法中最简单的之一。 无论是分类还是回归,衡量邻居的权重都非常有用,使较近邻居的权重比较远邻居的权重大。例如,一种常见的加权方案是给每个邻居权重赋值为1/ d,其中d是到邻居的距离。 邻居都取自一组已经正确分类(在回归的情况下,指属性值正确)的对象。虽然没要求明...

2022-12-24
A*搜索算法
A*搜索算法(A* search algorithm)是一种在图形平面上,有多个节点的路径,求出最低通过成本的算法。常用于游戏中的NPC的移动计算,或网络游戏的BOT的移动计算上。 该算法综合了最良优先搜索和Dijkstra算法的优点:在进行启发式搜索提高算法效率的同时,可以保证找到一条最优路径(需要评估函数满足单调性)。 在此算法中,如果以{\displaystyle g(n)}表示从起点到任意顶点{\displaystyle n}的实际距离,{\displaystyle h(n)}表示任意顶点{\displaystyle n}到目标顶点的估算距离(根据所采用的评估函数的不同而变化),那么A*算法的估算函数为: {\displaystyle f(n)=g(n)+h(n)}这个公式遵循以下特性: 如果{\displaystyle g(n)}为0,即只计算任意顶点{\displaystyle n}到目标的评估函数{\displaystyle h(n)},而不计算起点到顶点{\displaystyle n}的距离,则算法转化为使用贪心策略的最良优先搜索,速度最快,但可能得不出最优解...

2022-12-26
X算法
维基百科,自由的百科全书跳到导航跳到搜索在计算机科学中,X算法可用来求解精确覆盖问题。此名称最早在高德纳的论文《舞蹈链》中出现,他认为此算法是“试错法中最显而易见”的。 就技术而言,X算法是一个深度优先的不确定性回溯算法。由于X算法是一个解决精确覆盖问题的简洁方法,高德纳希望通过该算法体现舞蹈链数据结构的高效性,他把使用后者的X算法称为DLX。 X算法用由0和1组成的矩阵A来表示精确覆盖问题,目标是选出矩阵的若干行,使得其中的1在所有列中出现且仅出现一次。 X算法的步骤如下: 如果矩阵A为空(没有任何列),则当前局部解即为问题的一个解,返回成功;否则继续。 根据一定方法选择第c列。如果某一列中没有1,则返回失败,并去除当前局部解中最新加入的行。 选择第r行,使得Ar, c = 1(该步是不确定的)。 将第r行加入当前局部解中。 对于满足Ar, j = 1的每一列j,从矩阵A中删除所有满足Ai, j = 1的行,最后再删除第j列。 对所得比A小的新矩阵递归地执行此算法。 选择r的不确定性意味着算法将派生出若干独立的子算法,每个子算法都从其父算法中继承了去除部分行列的A矩阵。如果...
2022-12-26
二分查找算法
在计算机科学中,二分查找算法(英语:binary search algorithm),也称折半搜索算法(英语:half-interval search algorithm)、对数搜索算法(英语:logarithmic search algorithm),是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。 二分查找算法在最坏情况下是对数时间复杂度的,需要进行{\displaystyle O(\log n)}次比较操作({\displaystyle n}在此处是数组的元素数量,{\displaystyle O}是大O记号,{\displaystyle \log }是对数)。二分查找算法使用常数空间,对于任何大小的输入数据,算法使用的空间都是一样的。除非输入数据数量很少,否则二分查找算法比线性搜索更快,但数组必须事先被排...